谷歌针对LiteRT推出了一款全新的加速器,命名为高通AI引擎直通(QNN),其目的是增强配备骁龙8 SoC的高通安卓设备的AI性能表现。这款加速器能大幅提升性能,与CPU执行相比,速度最多可提升100倍;和GPU相比,速度也能提升10倍。
尽管现代安卓设备大多都配备了GPU硬件,但谷歌的软件工程师卢王、Wiyi Wanf与安德鲁·王认为,仅依赖GPU来处理AI任务或许会引发性能瓶颈。他们举例说明,像“在设备端运行计算量庞大的文本转图像生成模型,同时借助机器学习的分割技术处理实时相机画面”这类情况,即便是配置较高的移动GPU也可能难以应对。如此一来,很可能会造成用户体验出现卡顿以及掉帧的问题。
然而,许多移动设备现在配备了神经处理单元(NPUs),这些专门设计的AI加速器与GPU相比,可以显著加速AI工作负载,同时消耗更少的电力。
QNN是谷歌与高通密切合作开发的,用来替代之前的TFLite QNN代理。它通过集成广泛的SoC编译器和运行时,并通过简化的API提供给开发者,提供了统一和简化的工作流程。它支持90个LiteRT操作,目标是实现完整模型委托,这是实现最佳性能的关键因素。QNN还包括专门的内核和优化,进一步提升了像Gemma和FastLVM这样的LLM的性能。
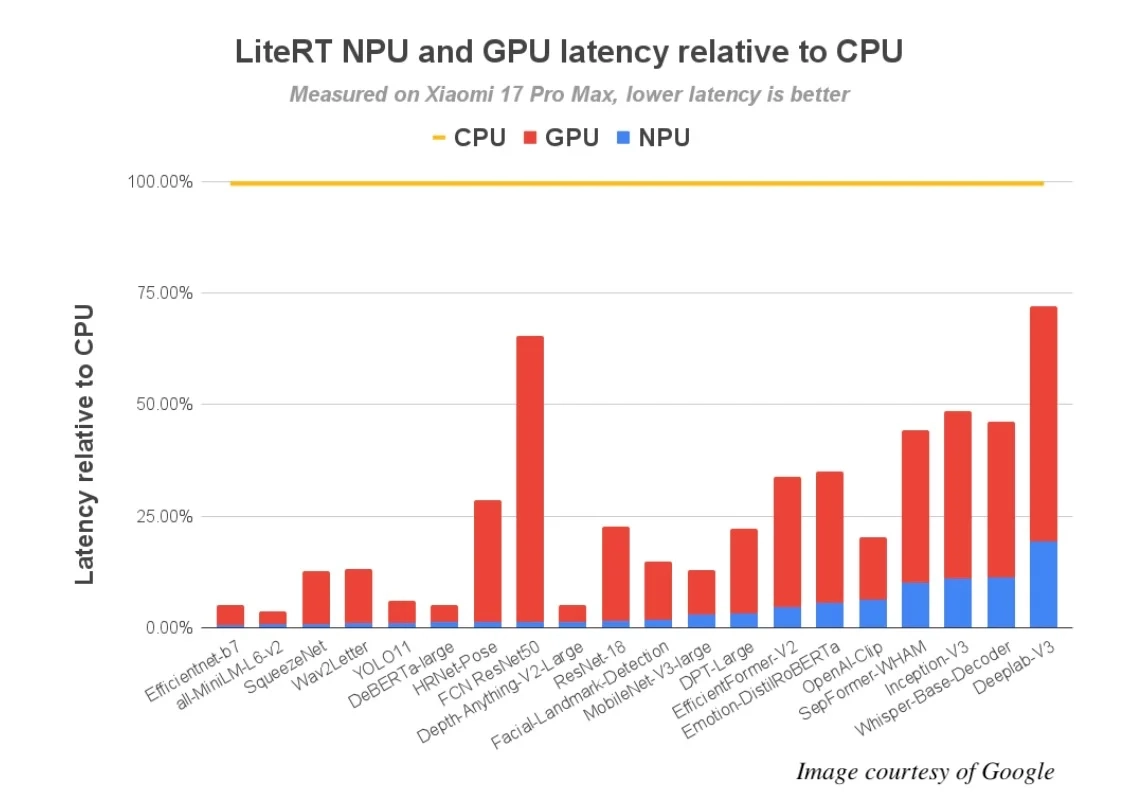
谷歌对72个机器学习模型进行了QNN基准测试,其中64个成功实现了完整的NPU委托。结果显示,与CPU执行相比,性能提升高达100倍,与GPU相比提升10倍。
在高通最新的旗舰SoC,骁龙8 Elite Gen 5上,性能提升显著:超过56个模型在NPU上运行时间不到5毫秒,而在CPU上只有13个模型能达到这一速度。这解锁了许多之前无法实现的实时AI体验。
谷歌工程师还开发了一个概念应用,利用了苹果FastVLM-0.5B视觉编码模型的优化版本。该应用几乎可以即时解释相机的实时场景。在骁龙8 Elite Gen 5 NPU上,它在1024×1024图像上的首次令牌时间(TTFT)仅为0.12秒,预填充速度超过11,000令牌/秒,解码速度超过100令牌/秒。苹果的模型通过int8权重量化和int16激活量化进行了优化。根据谷歌工程师的说法,这是解锁NPU最强大、高速int16内核的关键。
QNN仅适用于部分安卓硬件设备,具体来说主要是搭载骁龙8和骁龙8+ SoC的机型。若要开启使用,可前往NPU加速指南页面,并从GitHub上下载LiteRT。
上一篇: WeGame未完成任务自动下载的方法整理
下一篇: AI泡沫首次被戳破:GPU十年都难以存活
7月30日,沙盒MMO开放世界游戏《帝国神话》国服将与玩家见面

华为Pura 100系列处于打磨阶段:一大一小双尺寸 明年推出

《卧龙2:凤火连天》新片发布!主角设定揭晓,携手庞统共同复仇曹操

港服索尼PS+会员二三档游戏阵容公布,《浪人崛起》领衔登场

《留学模拟器》免费试玩活动上线啦!去夜店可要小心别被“斩杀”了
全球首款采用IJP OLED的笔记本要来啦——联想拯救者R9000P即将正式登场!

网传《看门狗》Switch2合集登零售商列表 kun回应称系伪造

《GTA6》首发暂不登陆PC,根源在于“优先在限制条件下进行开发”的思路